
There are a lot of new features in SQL Server 2016. Availability Groups by itself got a lot of new features. Being that I am the founder of the High Availability and Disaster Recovery Virtual Chapter, I plan on blogging about the new availability group features.
Today, I wanted to write about Automatic Seeding. Microsoft did an excellent job of explaining how to enable and monitor automatic seeding. I wanted to focus this post on my experience utilizing automatic seeding to seed an existing 600gb database in a test environment to test my endpoint network throughput.

The initial data synchronization easy button.
When you add a database to an availability group, the replicas must synchronize the data between the availability groups to join the database on the replicas. In the past, data initialization has been done with mirroring, log shipping, backup, and restores. Personally, I have been a big fan of log shipping for the initial data synchronization of VLDB’s especially when you need more than two replicas. Here is how I added a 60TB (Yes, TB not GB) database to an availability group that utilized multiple data centers.
Automatic seeding is a feature that has been in Azure SQL Databases for a while. It’s how the initial data synchronization occurs for Geo-Replication of Azure SQL Databases. Automatic seeding utilizes a VDI Backup to take a copy only backup and send it over the endpoint network to seed the replicas and then join the databases with the replicas. This eliminates the need to manually take full and log backups from the primary replica to all the secondary replicas. It will also join the database on the replicas for you.
Bonus Feature of Automatic Seeding
There is also a bonus feature of automatic seeding for DBA’s and Information Technology professionals. Even if you decide to not use automatic seeding I recommend testing this feature as automatic seeding can be a great way to stress your endpoint network to validate its throughput.
Background Information
This availability group has been configured with a separate 10Gbps network dedicated to endpoint traffic. Nothing else is active on the network or the replicas during the time of testing.
Setup
I configured the following performance monitor counters.
- Bytes Received/sec on Secondary replicas
- Bytes Sent/sec on Primary replica.
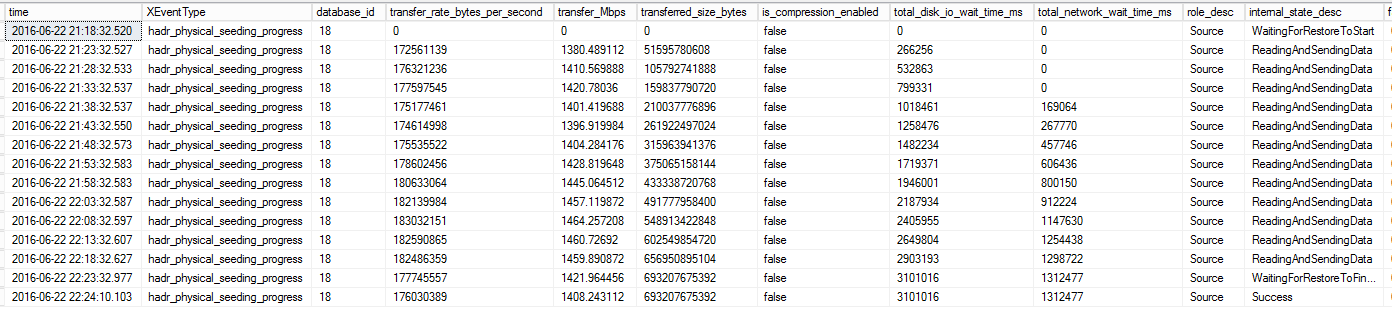
I also configured the following extended event session to monitor seeding activity on the primary and secondary replicas. We will focus on the “hadr_physical_seeding_progress” event today. We will talk about others in a future blog post.
CREATE EVENT SESSION [AlwaysOn_autoseed] ON SERVER ADD EVENT sqlserver.hadr_automatic_seeding_state_transition, ADD EVENT sqlserver.hadr_automatic_seeding_timeout, ADD EVENT sqlserver.hadr_db_manager_seeding_request_msg, ADD EVENT sqlserver.hadr_physical_seeding_backup_state_change, ADD EVENT sqlserver.hadr_physical_seeding_failure, ADD EVENT sqlserver.hadr_physical_seeding_forwarder_state_change, ADD EVENT sqlserver.hadr_physical_seeding_forwarder_target_state_change, ADD EVENT sqlserver.hadr_physical_seeding_progress, ADD EVENT sqlserver.hadr_physical_seeding_restore_state_change, ADD EVENT sqlserver.hadr_physical_seeding_submit_callback ADD TARGET package0.event_file(SET filename=N'autoseed.xel',max_file_size=(20),max_rollover_files=(4)) WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS, MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB, MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=ON) GO
The following T-SQL script is then used to read the results once your seeding process has completed. We will talk about the results in the results section below.
DECLARE @XFiles VARCHAR(300) = 'S:\MSSQL13.MSSQLSERVER\MSSQL\Log\autoseed*'
;WITH cXEvent
AS (
SELECT object_name AS event
,CONVERT(XML,event_data) AS EventXml
FROM sys.fn_xe_file_target_read_file(@XFiles, NULL,NULL,NULL)
where object_name like 'hadr_physical_seeding_progress')
SELECT
c1.value('(/event/@timestamp)[1]','datetime') AS time
,c1.value('(/event/@name)[1]','varchar(200)') AS XEventType
,c1.value('(/event/data[@name="database_id"]/value)[1]','int') AS database_id
,c1.value('(/event/data[@name="database_name"]/value)[1]','sysname') AS [database_name]
,c1.value('(/event/data[@name="transfer_rate_bytes_per_second"]/value)[1]','float') AS [transfer_rate_bytes_per_second]
,(c1.value('(/event/data[@name="transfer_rate_bytes_per_second"]/value)[1]','float')*8)/1000000.00 AS [transfer_Mbps]
,c1.value('(/event/data[@name="transferred_size_bytes"]/value)[1]','float') AS [transferred_size_bytes]
,c1.value('(/event/data[@name="database_size_bytes"]/value)[1]','float') AS [database_size_bytes]
,(c1.value('(/event/data[@name="transferred_size_bytes"]/value)[1]','float') / c1.value('(/event/data[@name="database_size_bytes"]/value)[1]','float'))*100.00 AS [PctCompleted]
,c1.value('(/event/data[@name="is_compression_enabled"]/value)[1]','varchar(200)') AS [is_compression_enabled]
,c1.value('(/event/data[@name="total_disk_io_wait_time_ms"]/value)[1]','bigint') AS [total_disk_io_wait_time_ms]
,c1.value('(/event/data[@name="total_network_wait_time_ms"]/value)[1]','int') AS [total_network_wait_time_ms]
,c1.value('(/event/data[@name="role_desc"]/value)[1]','varchar(300)') AS [role_desc]
,c1.value('(/event/data[@name="remote_machine_name"]/value)[1]','varchar(300)') AS [remote_machine_name]
,c1.value('(/event/data[@name="internal_state_desc"]/value)[1]','varchar(300)') AS [internal_state_desc]
,c1.value('(/event/data[@name="failure_code"]/value)[1]','int') AS [failure_code]
,c1.value('(/event/data[@name="failure_message"]/value)[1]','varchar(max)') AS [failure_message]
FROM cXEvent
CROSS APPLY EventXml.nodes('//event') as t1(c1)
Results
The 600 GB databases took about 66 minutes to seed across the network from a primary replica to the secondary replica. I noticed 1.4 Gbps of consistent throughput during the seeding process. This makes a lot of sense as it caps out around what the storage system can deliver in this environment.
The first thing I would look at for benchmarking throughput for network activity would be the bytes sent per second from the primary replica and bytes received per second on the secondary replicas.
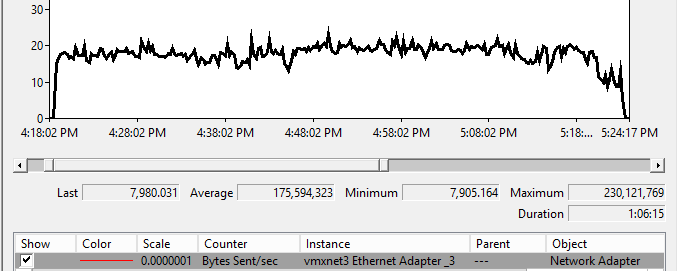
AG Seeding VLDB Primary Replica – Bytes Sent per Second
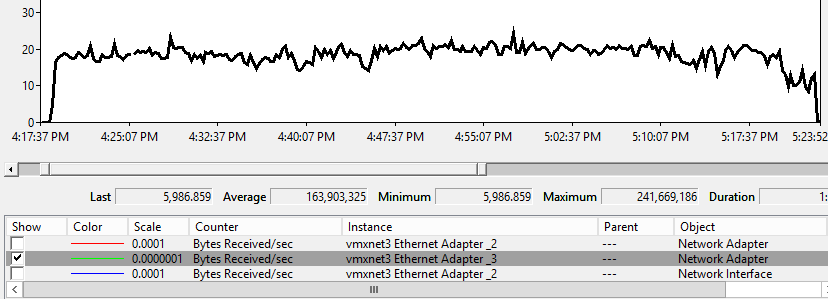
AG Seed VLDB Secondary Replica – Bytes Received per Second
I am seeing average around 1.4 Gbps. Normally, just looking at bytes sent and bytes received will be good enough for you to measure your throughput. Especially, when nothing else is utilizing the dedicated endpoint network. In the field, I usually do not see dedicated networks for endpoint traffic so I wanted to take this a step further and monitor with some of the new extended event events for automatic seeding.
Here is a look at the raw data from the extended event capture showing the progress and throughput of the seeding.
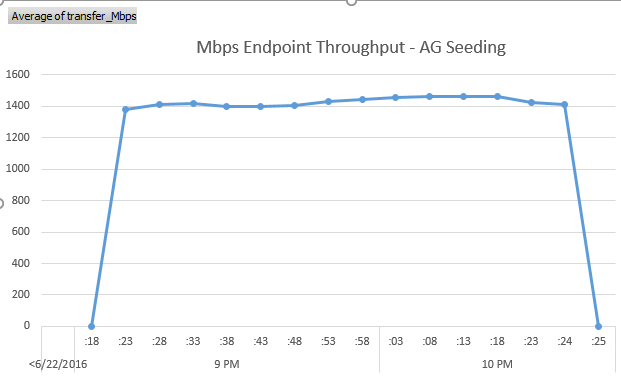
The following is a nice excel graph showing the throughput in Mbps. I added an extra row with zero for throughput just to show the rise and fall of network usages as seeding starts and completes.
My Thoughts
Initial data synchronization process just got a lot easier. I will use this for sure for adding new databases to availability groups. If you can live with your transactional log not being truncated during the seeding process I strongly encourage you to use automatic seeding.
I also did not use trace flag 9567 to enable compression during this test. It is why you saw compression not being enabled. If you have the CPU resources I recommend you test this as well.
Reference Links
- Initial Database Synchronization without Database and Log Backups
- Episode 2: Availability Group Automatic Seeding
- Books Online: Automatically initialize Always On availability group
For more great information on SQL Server subscribe to my blog and follow me on twitter.
