Today, I want to focus on how we can monitor wait statistics in an Azure SQL Database. In the past, I blogged about how you should benchmark wait stats with the box product. This process will give you misleading data in Azure SQL Database. You will want to focus on wait stats that are specific to your database as you are using shared resources in Azure SQL Databases.
Finding Database Waits Statistics

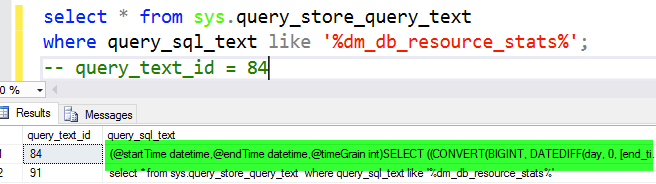
Query we are talking to you!
With an instance of SQL Server regardless of using IaaS or on-premise, you would want to focus on all the waits that are occurring in your instance because the resources are dedicated to you.
In database as a service (DaaS), Microsoft gives you a special DMV that makes troubleshooting performance in Azure easier than any other competitor. This feature is the dm_db_wait_stats DMV. This DMV allows us specifically to get the details behind why our queries are waiting within our database and not the shared environment. Once again it is worth repeating, wait statistics for our database in a shared environment.
The following is the script is a stored procedure I use to collect wait statistics for my Azure SQL Databases. I hope it is a helpful benchmarking tool for you when you need to troubleshoot performance in Azure SQL Database.
The Good Stuff
/***************************************************************************
Author : John Sterrett, Procure SQL LLC
File: AzureSQLDB_WaitStats.sql
Summary: The following code creates a stored procedure that can be used
to collect wait statistics for an Azure SQL Database.
Date: August 2016
Version: Azure SQL Database V12
---------------------------------------------------------------------------
For more scripts and sample code, check out
https://johnsterrett.com
THIS CODE AND INFORMATION ARE PROVIDED "AS IS" WITHOUT WARRANTY OF
ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING BUT NOT LIMITED
TO THE IMPLIED WARRANTIES OF MERCHANTABILITY AND/OR FITNESS FOR A
PARTICULAR PURPOSE.
************************************************************************/
If NOT EXISTS (Select 1 from sys.schemas where name = N'Waits')
execute sp_executesql @stmt = N'CREATE SCHEMA [Waits] AUTHORIZATION [dbo];'
GO
CREATE TABLE Waits.WaitStats (CaptureDataID bigint, WaitType varchar(200), wait_S decimal(20,5), Resource_S decimal (20,5), Signal_S decimal (20,5), WaitCount bigint, Avg_Wait_S numeric(10, 6), Avg_Resource_S numeric(10, 6),Avg_Signal_S numeric(10, 6), CaptureDate datetime)
CREATE TABLE Waits.BenignWaits (WaitType varchar(200))
CREATE TABLE Waits.CaptureData (
ID bigint identity PRIMARY KEY,
StartTime datetime,
EndTime datetime,
ServerName varchar(500),
PullPeriod int
)
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('CLR_SEMAPHORE')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('LAZYWRITER_SLEEP')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('RESOURCE_QUEUE')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('SLEEP_TASK')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('SLEEP_SYSTEMTASK')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('SQLTRACE_BUFFER_FLUSH')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('WAITFOR')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('LOGMGR_QUEUE')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('CHECKPOINT_QUEUE')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('REQUEST_FOR_DEADLOCK_SEARCH')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('XE_TIMER_EVENT')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('BROKER_TO_FLUSH')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('BROKER_TASK_STOP')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('CLR_MANUAL_EVENT')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('CLR_AUTO_EVENT')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('DISPATCHER_QUEUE_SEMAPHORE')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('FT_IFTS_SCHEDULER_IDLE_WAIT')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('XE_DISPATCHER_WAIT')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('XE_DISPATCHER_JOIN')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('BROKER_EVENTHANDLER')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('TRACEWRITE')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('FT_IFTSHC_MUTEX')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('SQLTRACE_INCREMENTAL_FLUSH_SLEEP')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('BROKER_RECEIVE_WAITFOR')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('ONDEMAND_TASK_QUEUE')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('DBMIRROR_EVENTS_QUEUE')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('DBMIRRORING_CMD')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('BROKER_TRANSMITTER')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('SQLTRACE_WAIT_ENTRIES')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('SLEEP_BPOOL_FLUSH')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('SQLTRACE_LOCK')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('DIRTY_PAGE_POLL')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('SP_SERVER_DIAGNOSTICS_SLEEP')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('HADR_FILESTREAM_IOMGR_IOCOMPLETION')
INSERT INTO Waits.BenignWaits (WaitType)
VALUES ('HADR_WORK_QUEUE')
insert Waits.BenignWaits (WaitType) VALUES ('QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP');
insert Waits.BenignWaits (WaitType) VALUES ('QDS_PERSIST_TASK_MAIN_LOOP_SLEEP');
GO
--DROP PROCEDURE Waits.GetWaitStats
CREATE PROCEDURE Waits.GetWaitStats
@WaitTimeSec INT = 60,
@StopTime DATETIME = NULL
AS
BEGIN
DECLARE @CaptureDataID int
/* Create temp tables to capture wait stats to compare */
IF OBJECT_ID('tempdb..#WaitStatsBench') IS NOT NULL
DROP TABLE #WaitStatsBench
IF OBJECT_ID('tempdb..#WaitStatsFinal') IS NOT NULL
DROP TABLE #WaitStatsFinal
CREATE TABLE #WaitStatsBench (WaitType varchar(200), wait_S decimal(20,5), Resource_S decimal (20,5), Signal_S decimal (20,5), WaitCount bigint)
CREATE TABLE #WaitStatsFinal (WaitType varchar(200), wait_S decimal(20,5), Resource_S decimal (20,5), Signal_S decimal (20,5), WaitCount bigint)
DECLARE @ServerName varchar(300)
SELECT @ServerName = convert(nvarchar(128), serverproperty('servername'))
/* Insert master record for capture data */
INSERT INTO Waits.CaptureData (StartTime, EndTime, ServerName,PullPeriod)
VALUES (GETDATE(), NULL, @ServerName, @WaitTimeSec)
SELECT @CaptureDataID = SCOPE_IDENTITY()
/* Loop through until time expires */
IF @StopTime IS NULL
SET @StopTime = DATEADD(hh, 1, getdate())
WHILE GETDATE() < @StopTime
BEGIN
/* Get baseline */
INSERT INTO #WaitStatsBench (WaitType, wait_S, Resource_S, Signal_S, WaitCount)
SELECT
wait_type,
wait_time_ms / 1000.0 AS WaitS,
(wait_time_ms - signal_wait_time_ms) / 1000.0 AS ResourceS,
signal_wait_time_ms / 1000.0 AS SignalS,
waiting_tasks_count AS WaitCount
FROM sys.dm_db_wait_stats
WHERE wait_time_ms > 0.01
AND wait_type NOT IN ( SELECT WaitType FROM Waits.BenignWaits)
/* Wait a few minutes and get final snapshot */
WAITFOR DELAY @WaitTimeSec;
INSERT INTO #WaitStatsFinal (WaitType, wait_S, Resource_S, Signal_S, WaitCount)
SELECT
wait_type,
wait_time_ms / 1000.0 AS WaitS,
(wait_time_ms - signal_wait_time_ms) / 1000.0 AS ResourceS,
signal_wait_time_ms / 1000.0 AS SignalS,
waiting_tasks_count AS WaitCount
FROM sys.dm_db_wait_stats
WHERE wait_time_ms > 0.01
AND wait_type NOT IN ( SELECT WaitType FROM Waits.BenignWaits)
DECLARE @CaptureTime datetime
SET @CaptureTime = getdate()
INSERT INTO Waits.WaitStats (CaptureDataID, WaitType, Wait_S, Resource_S, Signal_S, WaitCount, Avg_Wait_S, Avg_Resource_S,Avg_Signal_S, CaptureDate)
SELECT @CaptureDataID,
f.WaitType,
f.wait_S - b.wait_S as Wait_S,
f.Resource_S - b.Resource_S as Resource_S,
f.Signal_S - b.Signal_S as Signal_S,
f.WaitCount - b.WaitCount as WaitCounts,
CAST(CASE WHEN f.WaitCount - b.WaitCount = 0 THEN 0 ELSE (f.wait_S - b.wait_S) / (f.WaitCount - b.WaitCount) END AS numeric(10, 6))AS Avg_Wait_S,
CAST(CASE WHEN f.WaitCount - b.WaitCount = 0 THEN 0 ELSE (f.Resource_S - b.Resource_S) / (f.WaitCount - b.WaitCount) END AS numeric(10, 6))AS Avg_Resource_S,
CAST(CASE WHEN f.WaitCount - b.WaitCount = 0 THEN 0 ELSE (f.Signal_S - b.Signal_S) / (f.WaitCount - b.WaitCount) END AS numeric(10, 6))AS Avg_Signal_S,
@CaptureTime
FROM #WaitStatsFinal f
LEFT JOIN #WaitStatsBench b ON (f.WaitType = b.WaitType)
WHERE (f.wait_S - b.wait_S) > 0.0 -- Added to not record zero waits in a time interval.
TRUNCATE TABLE #WaitStatsBench
TRUNCATE TABLE #WaitStatsFinal
END -- END of WHILE
/* Update Capture Data meta-data to include end time */
UPDATE Waits.CaptureData
SET EndTime = GETDATE()
WHERE ID = @CaptureDataID
END
Special Wait Statistics Types
The following are wait statistics you will want to focus on specifically in Azure SQL Database. If you made it this far, I strongly encourage you to read how DTU is measured. That blog post will help you understand exactly why these waits can be signs of DTU pressure.
IO_QUEUE_LIMIT : Occurs when the asynchronous IO queue for the Azure SQL Database has too many IOs pending. Tasks trying to issue another IO are blocked on this wait type until the number of pending IOs drop below the threshold. The threshold is proportional to the DTUs assigned to the database.
LOG_RATE_GOVERNOR : Occurs when DB is waiting for quota to write to the log. Yes, Azure SQL Database is capping your transactional log writes to adhere to DTU.
SOS_SCHEDULER_YIELD: This occurs when a task voluntarily yields the scheduler for other tasks to execute. During this wait, the task is waiting in the runnable queue to get a scheduler to run. If your DTU calculation is based on CPU usage you will typically see these waits.
Want More Azure Articles?
If you enjoyed this blog post I think you will also enjoy the following related blog posts.
John Sterrett is a Microsoft Data Platform MVP and a Group Principal for Procure SQL. If you need any help with your on-premise or cloud SQL Server databases, John would love to chat with you. You can contact him directly at john AT ProcureSQL dot com or here.
Photo Credit:










{kind=link}