Want to make sure you don’t have errors, validate performance, and save money while making changes with Azure SQL Database, Azure SQL Managed Instance, SQL Server RDS in Amazon AWS? In this video, you will learn how to use the Data Experimentation Assistant to perform workload replay and compare your on-premise or cloud SQL Server workloads on-demand.
Replaying Workloads is your Secret Weapon to being a Rockstar!
I am not sure why but sometimes I am glutting for punishment. Maybe its why I try every backup and restore solution I can get my hands on? While Microsoft has done an amazing job at building the best relational database engine Azure Backup for SQL Server Virtual Machines has some architecture problems. In this post, I will showcase things you need to focus on, problems, and workarounds for your initial run with an Azure Backup for SQL Server VMs.
What’s Azure Backup for SQL Server Virtual Machines (VMs)?
If you take a look at Azure Backup they added functionality for backing up SQL Server databases inside an Azure VM. This seems like a really cool feature. Let’s use the same technology we use to backup our VM’s to also backup our databases. You know the whole one-stop-shop for your disaster recovery needs. Comes with built-in monitoring and it also eliminates the struggle some people have with setting up certificates, encryptions, purging old backups in blob storage, backups and restores from blob storage. It is really nice to also have a similar experience as restoring Azure SQL Databases as well.
Unfortunately, the product doesn’t work as expected at this point in time. I would expect any database backup tool to be able and backup the system databases by default without any customization. Therefore, Last night I setup my first Azure Backup for SQL Server Virtual Machines in the Backup Vault and this morning you can see my results below.
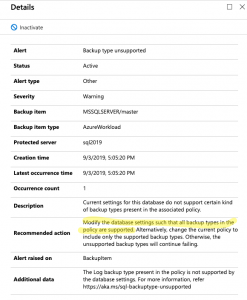
Azure Backup for SQL Server VM’s gets 0/3 system databases backed up by default
Now we will dig into concerns and initial problems with Azure Backup for SQL Server Virtual Machines (VMs).
Automatically Backup New Databases
Having the ability to backup new databases automatically is taken for granted. So much, that I noticed that Azure Backup for SQL Server VM’s will not automatically backup new databases for you. That’s right. Make sure you remember to go in and detect and select your new database every time you add a database or you will not be able to recover.
Azure Backup for SQL Server VM’s has an interesting feature called Autoprotect. This should automatically backup all your databases for you. Unfortunately, this does not work. Yes, I double-checked by enabling autoprotect for a VM and I added a new database. The database didn’t get backed up so I had to manually add the database.
Simple Recovery Problems
Looking into the failures for my system database backups I noticed something interesting in the log for the master database. It looks like you will get errors with the only SQL Server backup policy created by default. The reason is the policy includes transactional log backups and as you know its impossible to take a transactional log backup if your database utilizes the simple recovery model. Now, most backup tools know how to roll with databases in simple and full recovery.
Looks like Azure Backup for SQL Server VM’s is not one of these tools that easily allow you to mix databases utilizing both simple and full recovery models.
Yup, simple recovery model is no bueno..
So, how do we get around this? It is not too hard. Just create a new backup policy that does not include transactional log backups and assign it to your databases that utilize the simple recovery model.
Transactional Log Backup Problems
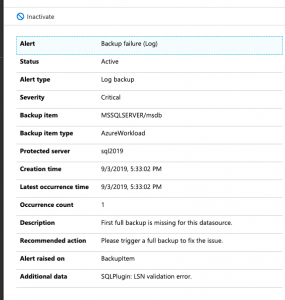
So, what happens when you try to take a transactional log backup of a database that doesn’t have a full backup? It fails. This is by design. If you try to take a log backup in this scenario with T-SQL it will fail as well. That said, several 3rd Party open source backup solutions like my recommended one can gracefully handle this for you. It can take a full backup instead of the log backup. I have grown to expect this behavior.
Here is what you will see in the logs of Azure Backup for SQL Server VM’s.
You have to force a full backup or wait until the scheduled full backup occurs. Yuck!
So, the workaround here is simple. You can force a backup. This will start the process of allowing your schedule log backups to work as designed. You could also wait until the scheduled full backup runs but know this means you will not have point in time recovery until that full backup runs. There should be an option to perform a full backup instead of a transactional log backup if a full backup does not exist. This would prevent the transactional log scheduled backups from failing.
Things to Know!
Azure Backup for SQL Server VM’s pricing goes off of storage as well as instances of SQL. By default, compression is not used for the SQL Server Backups. You will most likely want to make sure you enable this to save some money.
There are many documented limitations that we didn’t cover in this blog post. Some shocking ones to me are SQL Server Failover Cluster Instances and don’t configure backup for more than 50 databases in one go
Speaking on Migrating to Azure SQL Database at Ignite 2017
This week I will have two talks on migrating existing database to Azure SQL Databases at Microsoft Ignite. If you are there and curious about migrating your existing databases we would love to talk with you.
This past weekend I had the privilege of speaking at SQL Saturday Houston. I enjoyed catching up with some friends while I also took the time to make some new ones as well.
This was the first time I presented my Azure Databases for DBA’s talk at a conference. I got some great feedback and it was a lot of fun. I ended up using videos for the demos to make sure they would fit within the timeline of the presentation. Running the High Availability and Disaster Recovery Virtual Chapter I am always thinking of backup strategies this even includes my own demos 😉
At the end of the day I gave my “Why Did My Plan Change: Intro to Query Store” presentation. I was able to tell some real-world stories about lessons learned while monitoring plan changes and explain how upgrades can greatly improve performance when you find the few queries that run slower after an upgrade and fix them.
THE CAR THAT WOULDN’T START
Leaving the event I though I was on my way to the after party when I realized my 1990 Volvo wouldn’t start. Some people would be upset and frustrated but looking back a few days later, I was blessed. Let me explain. Instead of being stranded by myself Jamey Johnston stayed to help. He made sure I would be okay. The bonus in this for me was that I was able to chat with Jamey and get to know him better. He is an amazing guy. I wish we had a lot more people like Jamey in our SQL Server Community!
If you’re not familiar, T-SQL Tuesday is a blogging party hosted by a different
Transactional Replication for Azure Databases
person each month. It’s a creation of Adam Machanic (b|l|t), and it’s been going on for a long time (77 months to be exact). The host selects a topic, defines the rules (those are almost always the same), and then everyone else blogs about it. Once the deadline is reached, the host will summarize each of the submitted posts on their site/blog.
This month, Jens Vestergaard is the host and he is asking the following question. What is your favorite SQL Server feature? I am going to use this opportunity to talk about my favorite new Azure Database Feature that was added this past year.
TRANSACTIONAL REPLICATION TO AZURE DATABASES
That’s right, and this won’t surprise my #SQLFamily because they already know that I love some transactional replication. Yes, as a Database Administrator I love this feature more than Query Store. I also think this will be a game changer. Here are three reasons why.
The Proof Of Concept Your Boss Will Approve
So you are interested in trying out Azure Database but your boss says, “Yea, that’s not going to happen! Implementation risk is too high.” Go ahead and insert basically any sentence excuse you want. I am sure you could compile your own list. This is where you can tell your boss, “Do you remember the support calls we get when James in Finance runs his ad-hoc queries (more on this in a bit) or the that John was using Access again against our database? Wouldn’t it be nice if we can offload that activity and use it as a use case to see if Azure Database can work for us at the same time?” Would it be nice to do this without buying new hardware? Wouldn’t it be nice if this copy of data was kept in-sync so you didn’t have to refresh it? Wouldn’t it be nice if it worked using normal tools that are included with SQL Server?
That’s right, with transactional replication we can now get those users who we don’t want anywhere near our teir-1 OLTP critical databases in Azure. You can provide them their own data center and let the reporting users be your test case for working with Azure Databases. If it doesn’t work, you can easily bring them back on-prem.
Offloading Real-World Ad-Hoc Reporting
In the field, I see a lot of people using Availability Groups to have a near real-time replica for reporting. I talked a little bit about this above. What isn’t mentioned here is you have to maintain a Windows Failover Cluster, Quorum, Active Directory (Unless using Windows 2016 Preview) and more. This gets you a replica that is just a copy of the database. What does this mean? You cannot change database objects like security, indexes, etc. Also, what if you don’t need the whole database(s) for reporting? If not, you can replicate only the data you truly need.
So, let’s recap here. You only have to replicate the data that you need. You can have different security and indexes on your reporting subscriber database(s). The reporting subscriber database can be scaled up or down as needed based on your needs. The reporting database can now be an Azure Database. Folks, I call this a huge win!
Easy Migration to Azure Database
As databases get bigger they become harder to migrate. I learned this first hand when I had to migrate and make an 80TB database highly available with Availability Groups. The larger your database the more downtime is required to deploy your existing database to an Azure Database. Well this isn’t true anymore if you have primary keys on every table. You could pre-sync the data migration process in advance. This could greatly cut down your migration time and get you to no downtime during your migration.
In my next blog post, I will walk you through a step by step guide to creating a Transactional Replication Subscriber that uses an Azure Database.
Recently, I had the pleasure of writing another article that was included the Notes From the Field series that is hosted out on SQLAuthority.com. This tip was my first one working with Azure. To me its remarkable how quickly you can spin up an instance to help you build out a proof of concept. In this tip I show you how you can build your very first windows azure box.
This site uses functional cookies and external scripts to improve your experience. Which cookies and scripts are used and how they impact your visit is specified on the left. You may change your settings at any time. Your choices will not impact your visit.
NOTE: These settings will only apply to the browser and device you are currently using.