Unfortunately, with Azure SQL Database you are not able to take an existing SQL Server Backup and restore it on an Azure SQL Database server. We are talking about Microsoft’s database as a service (DaaS) offering, not Azure VMs also known as infrastructure as a service (IaaS). The only current way to migrate an existing database is to move the schema and the data, period. We have some good tools that can make this seamless, especially with smaller databases and outage windows. You can easily use SQLPackage.exe (My recommended tool), SSMS Wizard , or import/export bacpacs.

Migrating Existing Databases to Azure SQL Database
This is great, except for the case I want to talk about today. What if you need to do a live migration with as little downtime (business wants no downtime) as possible with bigger databases. For example, say and existing 50 GB to 500GB database? Your only, option today is a good old friend of mine called transactional replication. You see, you can configure transactional replication and have the snapshot occur and all data in your current production system can be syncing live with your Azure SQL Database until it’s time to cutover which will make your cutover downtime as short as possible.
Below I will give you step by step instructions on how you can configure your subscriber. This would be your Azure SQL Database. The publisher would be your existing production database which could either be on-premise or an Azure VM.
Prereqs
To make this blog post as consumable as possible, we will assume a few prereqs have been completed. Links in the reference section are provided in case you might want help with the following prereqs.
- Current production database has a primary key on all tables that need to be migrated. This is a requirment for transactional replication.
- A new empty Azure SQL Database exists.
- Azure SQL Database Firewall includes your distributor SQL Server (more in this below)
- You have an SQL Authenticated Account configured for your Azure SQL Database
- Publication currently exists
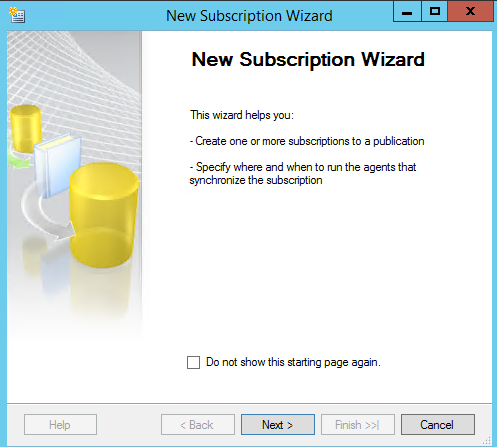
Step One:
Below we will start creating our subscription by utilizing an existing publication. For this article, we will use AdventureWorks. We start by creating a new subscription. I assume you have an existing publication on your primary server and that it is configured. We will use the same server for the distribution agent and the distribution database.
Next, we will walk through the wizard.
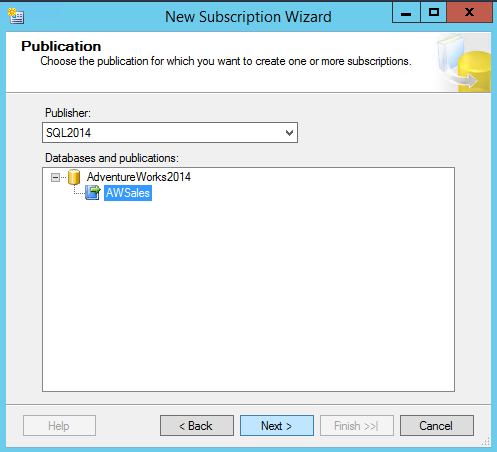
Step Two:
Select the publication you would want to use to add the new subscriber to use the empty Azure SQL Database. Remember in this case, were going to use this subscriber to migrate the schema and data to a new Azure SQL Database.
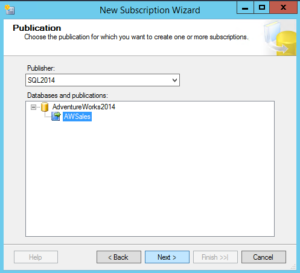
Step Three:
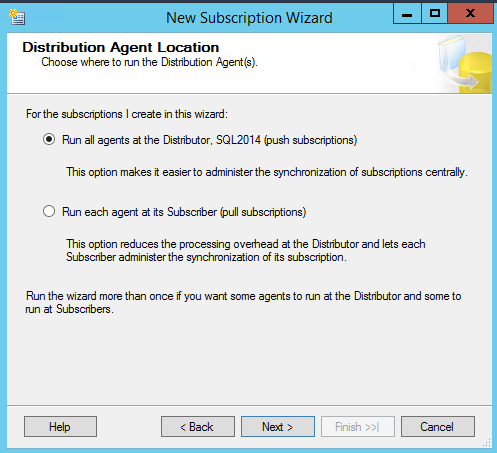
Now, you will need to configure the distribution properties. With Azure SQL Databases you will have no access to the OS and only the database. Therefore, you will need to create a push subscription. A push subscription is a nice way of saying all the agents that initialize the data sync, capture and send data are configured on the distributor server.
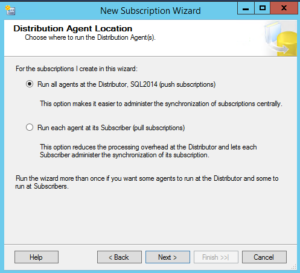
NOTE: If you plan on having a lot of publications it is recommended to use an individual SQL Server to isolate your distribution databases.
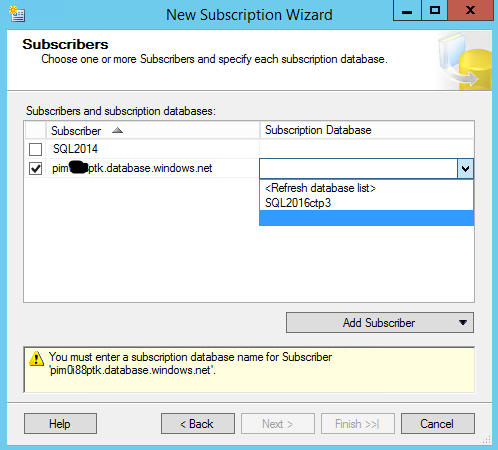
Step Four:
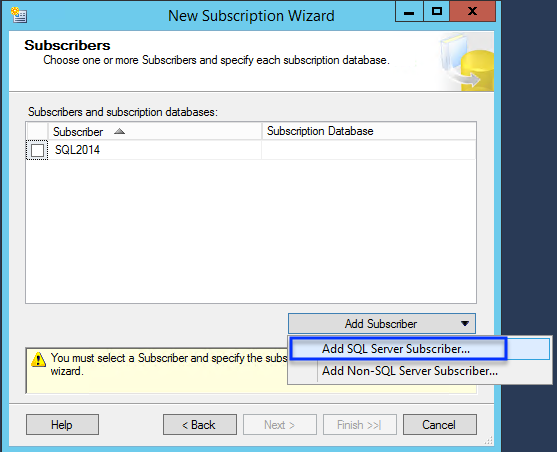
Now we will select where our subscriber will reside. The subscriber will be the Azure SQL Database that we are migrating too.
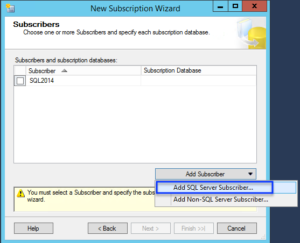
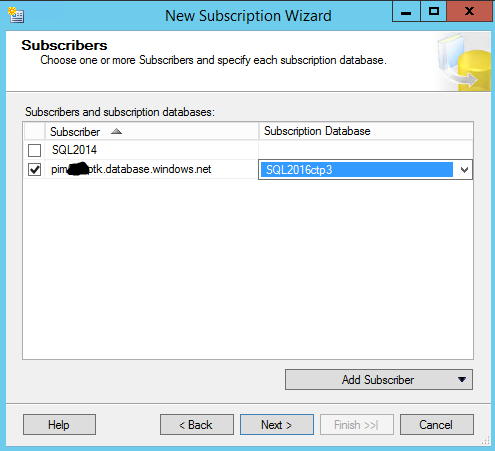
Now you will be able to select your database. In this case, we are going to use SQL 2016ctp3 database. This is an empty database that was created in the prereqs.
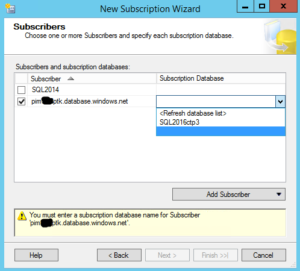
NOTE: Your publisher and distribution SQL Servers must be on a supported version of SQL Server to have Azure SQL Database as a subscriber or you will not be able to select your Azure SQL Database Server as a new subscriber. Trust me, I learned this initially the hard way.
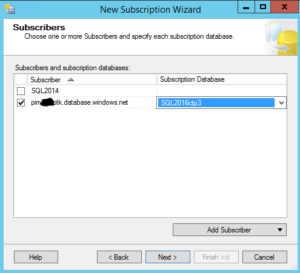
Step Five:
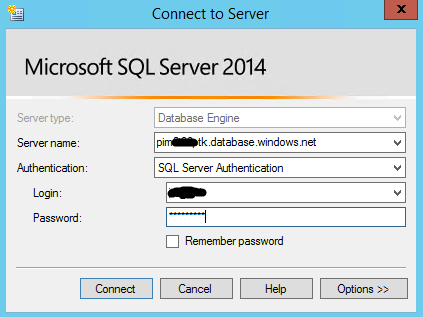
Now that our subscriber database is selected we need to define how we are going to connect to our subscriber.
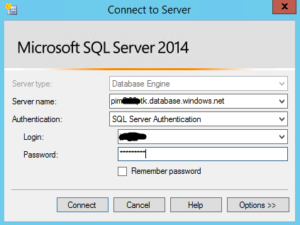
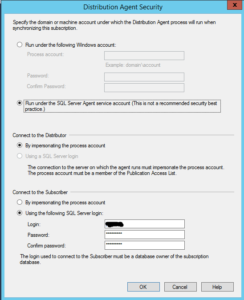
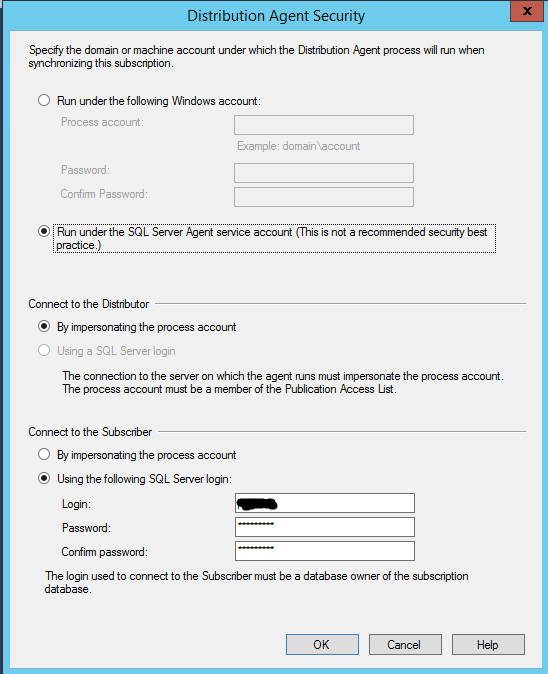
We will use SQL Server authentication using an account on your Azure SQL Database that will allow you to create the schema and move the data. You will also need to update your SQL Azure firewall to include your existing distribution SQL Server as mentioned in the prereq section.
For simplicity of this guide, we are going to run the distribution agent under the SQL Agent Service account. Ideally, you would want a separate account that only had the security needed for transactional replication.
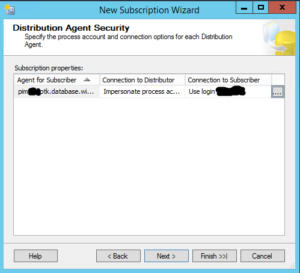
Next, we will define how often we will synchronize the data. We will select to run continuously. You could also have this run on a schedule as well.
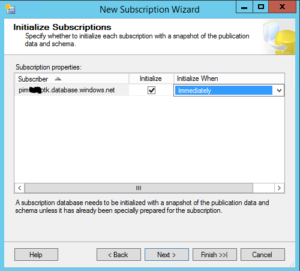
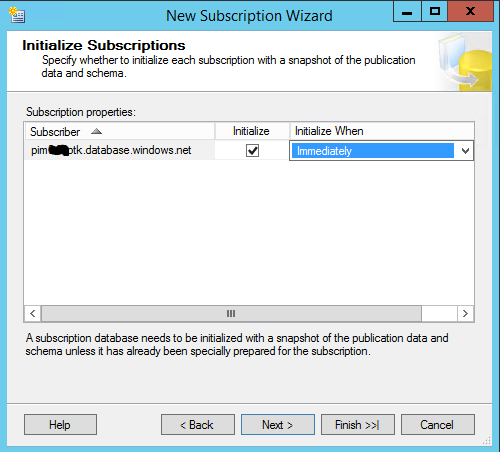
Now we select when to initialize the subscription. Initializing the subscription will execute the snapshot agent (process) that will initialize building the schema and bulk inserting data from the publisher to the distributor and then this data will be sent to the subscriber.
NOTE: The snapshot process will require a schema lock on the publisher database so make sure you initialize at a time when the schema lock is appropriate. In this article, we will initialize immediately.
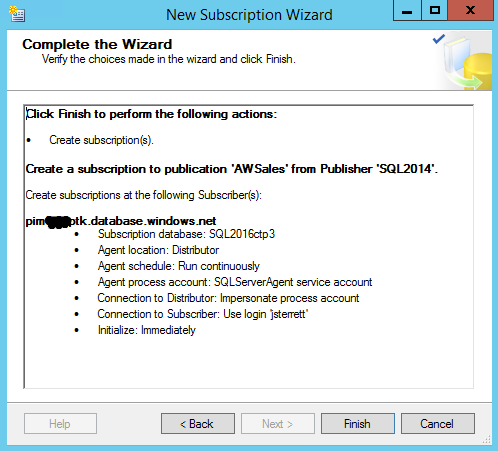
Step Six:
Now the hard work is done. We will go through the final processes of adding the new subscription with the wizard provided with SSMS.


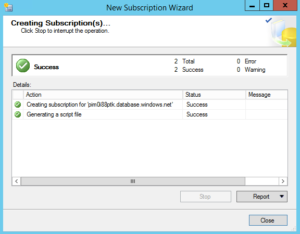
Finally, once the New Subscription Wizard is successful, you will see your subscription like shown in the image below. You can then monitor the synchronization just like you would with any on-prem transactional replication configuration.
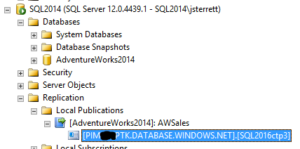
Conclusion
Configuring an Azure SQL Database as a subscriber is a lot easier than many IT Professionals would initially think. It’s also the best current option to reduce downtime required to synchronize data during a migration of an existing database. The data sync is done in advance and data changes will be kept in sync.
Once data is synchronized, you can stop access to the current production server and remove the subscriber and let the users access the new Azure SQL Database.
Keep in mind, as of the time of publishing this blog post an Azure SQL Database can only be a subscriber and not a publisher in transactional replication. What does this mean to you? Do performance and acceptance testing because you would have to generate a bacpac and export it and import it if you decide to move away from Azure SQL Database.
Additional Reference
John Sterrett is a Microsoft Data Platform MVP and a Group Principal for Procure SQL. If you need any help with your on-premise or cloud SQL Server databases, he would love to chat with you. You can contact him directly at john AT ProcureSQL dot com or here.




{kind=link}