In SQL Server 2012 we got this great new high availability feature called availability groups. With readable secondaries under the covers it can be harder to figure out the following two questions. When did the availability group failover? Where did the availability group go when the failover occurred? The goal of this blog post is to help you answer these questions.
AlwaysON Extended Event
One of the things I really like about Availability Groups is that there is a built-in extended event named “ALwaysOn_health” that runs and captures troubleshooting information. I took a look at the extended event and noticed that there are several error numbers that were included in the filter for this extended event. This is shown below as I scripted out the default extended event for a quick review.
CREATE EVENT SESSION [AlwaysOn_health] ON SERVER
ADD EVENT sqlserver.alwayson_ddl_executed,
ADD EVENT sqlserver.availability_group_lease_expired,
ADD EVENT sqlserver.availability_replica_automatic_failover_validation,
ADD EVENT sqlserver.availability_replica_manager_state_change,
ADD EVENT sqlserver.availability_replica_state_change,
ADD EVENT sqlserver.error_reported(
WHERE ([error_number]=(9691) OR [error_number]=(35204) OR [error_number]=(9693) OR [error_number]=(26024) OR [error_number]=(28047)
OR [error_number]=(26023) OR [error_number]=(9692) OR [error_number]=(28034) OR [error_number]=(28036) OR [error_number]=(28048)
OR [error_number]=(28080) OR [error_number]=(28091) OR [error_number]=(26022) OR [error_number]=(9642) OR [error_number]=(35201)
OR [error_number]=(35202) OR [error_number]=(35206) OR [error_number]=(35207) OR [error_number]=(26069) OR [error_number]=(26070)
OR [error_number]>(41047) AND [error_number]<(41056) OR [error_number]=(41142) OR [error_number]=(41144) OR [error_number]=(1480)
OR [error_number]=(823) OR [error_number]=(824) OR [error_number]=(829) OR [error_number]=(35264) OR [error_number]=(35265))),
ADD EVENT sqlserver.lock_redo_blocked
ADD TARGET package0.event_file(SET filename=N'AlwaysOn_health.xel',max_file_size=(5),max_rollover_files=(4))
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=ON)
GO
This got me interested in learning why these specific errors were included in the extended event session created specifically for managing Availability Groups. Knowing that the descriptions for errors are kept in the sys.messages table I did a little digging.
System Messages
Taking the error numbers from the AlwaysON_health extended event I was able to build the following query to get the description of the errors included in the extended event.
SELECT *
FROM sys.messages m where language_id = 1033 -- English
--AND m.message_id =1480
AND ([message_id]=(9691) OR [message_id]=(35204) OR [message_id]=(9693) OR [message_id]=(26024) OR [message_id]=(28047)
OR [message_id]=(26023) OR [message_id]=(9692) OR [message_id]=(28034) OR [message_id]=(28036) OR [message_id]=(28048)
OR [message_id]=(28080) OR [message_id]=(28091) OR [message_id]=(26022) OR [message_id]=(9642) OR [message_id]=(35201)
OR [message_id]=(35202) OR [message_id]=(35206) OR [message_id]=(35207) OR [message_id]=(26069) OR [message_id]=(26070)
OR [message_id]>(41047) AND [message_id]<(41056) OR [message_id]=(41142) OR [message_id]=(41144) OR [message_id]=(1480)
OR [message_id]=(823) OR [message_id]=(824) OR [message_id]=(829) OR [message_id]=(35264) OR [message_id]=(35265))
ORDER BY Message_id
Now we will focus on one particular error message. This is error message 1480. Looking at the description below you will see that every time a database included in an availability group or in database mirroring changes its role this error occurs.
The %S_MSG database “%.*ls” is changing roles from “%ls” to “%ls” because the mirroring session or availability group failed over due to %S_MSG. This is an informational message only. No user action is required.
When did my AlwaysOn Availability Group Failover?
By now it should not be a big surprise to see how you can figure out when our availability group failed over. To answer this question we are going to filter the “AwaysOn_health” extended event for error_number 1480.
The “AlwaysOn_health” extended event target is to file and by default it will utilize the default log folder for SQL Server. Also keep in mind, that by default the target does rollover for 4 5 MB files for a total of 20 MB. If you are constantly having events occur data will be purged.
For my server used for this blog post my path is “C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\Log\” if this is not your path you will need to modify line 2 in the script below.
;WITH cte_HADR AS (SELECT object_name, CONVERT(XML, event_data) AS data
FROM sys.fn_xe_file_target_read_file('C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\Log\AlwaysOn*.xel', null, null, null)
WHERE object_name = 'error_reported'
)
SELECT data.value('(/event/@timestamp)[1]','datetime') AS [timestamp],
data.value('(/event/data[@name=''error_number''])[1]','int') AS [error_number],
data.value('(/event/data[@name=''message''])[1]','varchar(max)') AS [message]
FROM cte_HADR
WHERE data.value('(/event/data[@name=''error_number''])[1]','int') = 1480
Below you will see an example of the result set which shows my last failover.

You could also utilize the Extended Event GUI to watch data. We will skip that today as I would recommend using T-SQL so you can find failovers in multiple Availability Groups on different servers. We will go into more detail about this process a little later in the blog post.
How Do We Become Proactive?
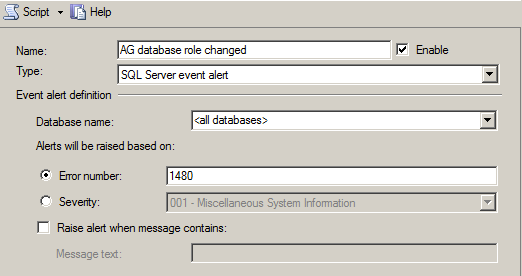
If you want an action to occur when an database inside an availability group changes roles to be proactive you can configure an SQL Agent Alert. An SQL Agent alert can performs an actions like sending an email to your DBA team or running another SQL Agent job to perform your required action.
The following shows you how to configure this alert via the SSMS user interface.
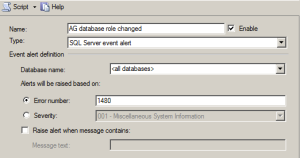
How Do We Report failovers across the Enterprise?
Central Management Server (CMS) is your best friend for building reports to show Availability Group failovers across the enterprise. You can build an CMS group for your SQL 2012 instances and copy and paste the query above to detect Availability Group failovers.
NOTE: This assumes you have an standard install process that keeps the default log path the same across your SQL Server 2012 instances. I strongly encourage that you have an automated SQL Install process that keeps using the same path for all your installs but we will keep that blog post for another day.




 You kid brother just messed up a database migration. You now have sixty seconds to migrate a 30 GB database or you kid brother is…
You kid brother just messed up a database migration. You now have sixty seconds to migrate a 30 GB database or you kid brother is…