In SQL Server 2016 we saw Query Store. Query Store was a game changer to help database administrators identify troublesome queries. Query Store helps DBAs make those queries run faster. Microsoft’s marketing team even jumped on to help coin the phrase, “SQL Server It Just Runs Faster.” With SQL Server 2017, this started to get even better with automatic tuning. Don’t worry database administrators. Automatic Tuning will just enhance your career and not replace it.
SQL Server 2017 Automatic Tuning looks for queries where execution plans change and performance regresses. This feature depends on Query Store being enabled. Note, even if you don’t turn on Automatic Tuning you still get the benefits of having access to the data. That is right. Automatic Tuning would tell you what it would do if it was enabled. Think of this as free performance tuning training. Go look at the DMVs and try to understand why the optimizer would want to lock in an execution plan. We will actually go through a real-world example:
Automatic Tuning with SQL Server 2017
First, let’s take a quick look at the output of the data. You can find the query and results we will focus on below.
SELECT reason, score,
script = JSON_VALUE(details, '$.implementationDetails.script'),
planForceDetails.*,
estimated_gain = (regressedPlanExecutionCount+recommendedPlanExecutionCount)
*(regressedPlanCpuTimeAverage-recommendedPlanCpuTimeAverage)/1000000,
error_prone = IIF(regressedPlanErrorCount>recommendedPlanErrorCount, 'YES','NO')
--INTO DBA.Compare.Tunning_Recommendations
FROM sys.dm_db_tuning_recommendations
CROSS APPLY OPENJSON (Details, '$.planForceDetails')
WITH ( [query_id] int '$.queryId',
[current plan_id] int '$.regressedPlanId',
[recommended plan_id] int '$.recommendedPlanId',
regressedPlanErrorCount int,
recommendedPlanErrorCount int,
regressedPlanExecutionCount int,
regressedPlanCpuTimeAverage float,
recommendedPlanExecutionCount int,
recommendedPlanCpuTimeAverage float
) as planForceDetails;
I will break the results down into two photos to make them fit well in this blog post.

Free Tuning Recommendations with SQL Server 2017 (1/2)

Free Tuning Recommendations with SQL Server 2017 (2/2)
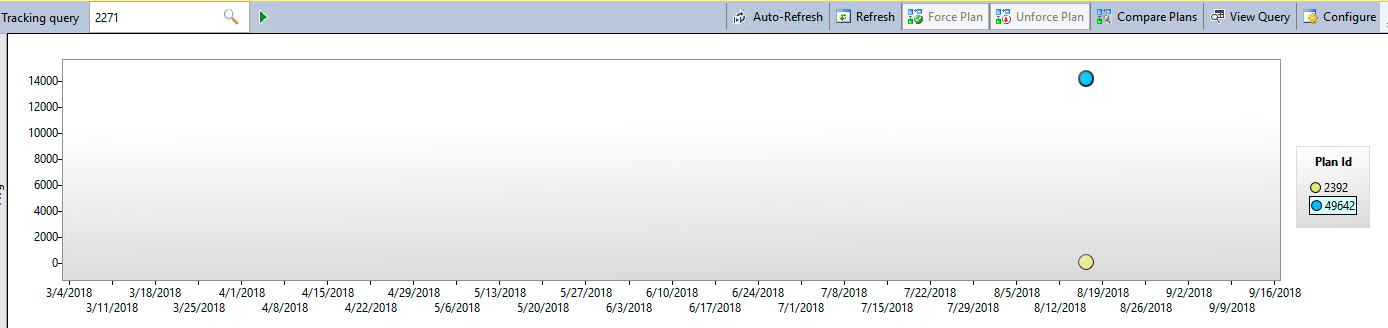
Now we know in the query store query_id 2271 has CPU time changing from 7,235ms to 26ms. That’s a big difference. Let’s take that query and look at its findings by using the tracked query report inside SSMS.
Find my Changed Query. Did the plans change?
Here we can see the major difference between the two execution plans. One is averaging over 14 seconds in duration while the other is under a second.
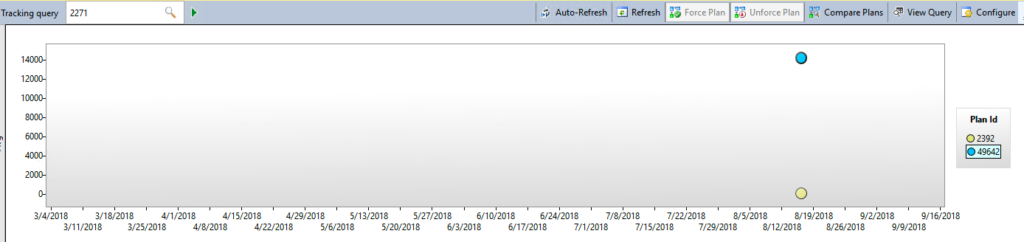
Query Store showing the performance difference between the two plans
Now we can select both plans on the screen above and look at the execution plans side by side inside of SSMS. When doing so, we see the common example of the optimizer determining if it is better to scan an index vs a seek with a key lookup.

Using SSMS to compare auto tuning recommended query.
To complete the example I want to point out that automatic tuning would lock in the index seek plan (Plan 2392). In SQL Server 2016 you can do this as well manually inside Query Store. With SQL Server 2017 it can be done automatically for you with Automatic Tuning. If you have ever woken up to slow performance due to an execution plan changing and performance going through the drain this might be a life saver.
If you would like to learn about performance tuning changes in SQL Server 2016 and 2017 sign up for our newsletter or catch me talking about these features at SQL Saturday Denver and SQL Saturday Pittsburgh this month. If you need any help with tuning or upgrading contact us. We would love to chat with you!